ID Unification とは何か?#
複数のテーブル間を、複数の識別子を使用して縫い合わせ、ユーザーごとにユニークな顧客 ID (canonical_id) を付与する作業を意味する。言い換えると「複数のユーザーデータの中から cookie_id やメールアドレスなどの識別子を手がかりに “同じ人” をまとめる作業である。 顧客データはデータソースごとに異なる識別子を持っていることがほとんどである。なので、それらを単に集めてきただけでは互いのデータソースが紐づかず、活用することができないためこの ID Unification と呼ばれる作業が必ず必要になってくる。
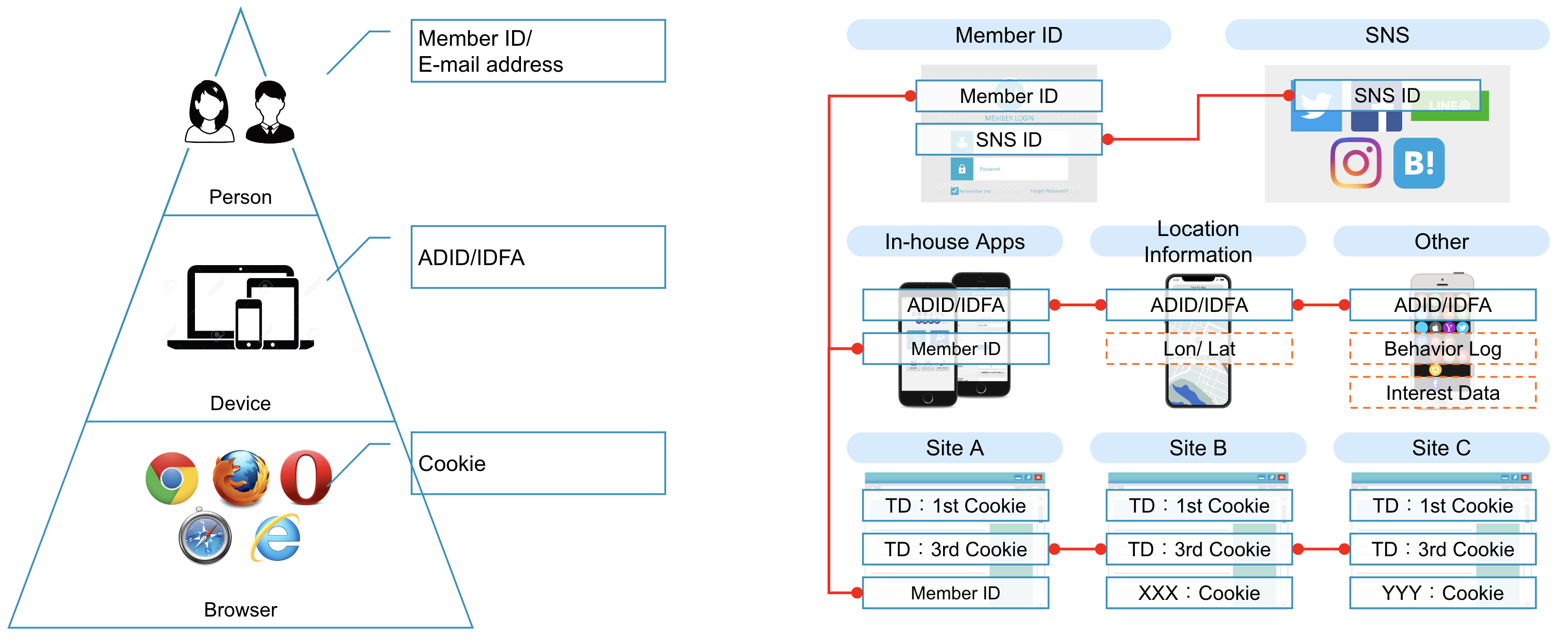
Fig. 1 異なる識別子同士の関係#
上の図は、ユーザーが持つ ID (識別子) が何に紐づいて保持されているかを示したもので、以下にタイプごとの代表的な ID を紹介している。ID Unification では、同じタイプの ID だけでなく、これらのタイプの異なる ID についても複数のデータを通して縫い合わせを行っていき、個人を特定するものである。
ユーザーに紐づく ID#
各サービス毎に発行される会員 ID や登録に使用されるメールアドレスが統合に用いられる ID となる。
例:member_id, customer_id, email address
デバイスに紐づく ID#
アプリのログを取得する際に端末単位で発行される ADID/IDFA が統合に用いられる ID となる。
例:ADID/IDFA
ブラウザに紐づく ID#
ブラウザ×発行元で共通となる Cookie が統合に用いられる。1st と 3rd があり、データを横断して縫い合わせを行うためには双方の cookie_id があると都合が良い。
例:cookie_id
TD の提供する ID Unification 機能 (Workflow) について#
TD では、全ユーザーが利用できる標準機能として、ID Unification を実行する Workflow を提供している。 このツールを使う際にユーザー側で記述する必要があるのは、主に
Unification WF を呼び出す dig ファイル
ID Unification を行うデータソースや、縫い合わせキーを定義する yml ファイル
の2つになる。
1. Unification WF を呼び出す dig ファイル#
+call_unification:
http_call>: https://api-cdp.treasuredata.com/unifications/workflow_call
headers:
- authorization: TD1 ${secret:td.apikey}
method: POST
…
Unification WF をコールするための dig ファイル。http_call で呼び出す形になる。この仕様により、github から WF コードをダウンロードすることもなく、また、アップデートも全ユーザーで一律に行えるというメリットがある。
2. ID Unification を行うデータソースや、縫い合わせキーを定義する yml ファイル#
name: test_id_unification_ex1
keys:
- name: td_client_id
- name: td_global_id
tables:
- database: test_id_unification_ex1
table: ex1_site_aaa
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
…
この yml ファイルにおいて、ソーステーブルと、縫い合わせのために使う key などの設定などを記述していく。前述の dig ファイルは多くのユーザー間でそれほど変わらないものに対して、この yml ファイルは完全にデータに依存するので、ユーザーが自身のデータの構成を把握し、丁寧に記述していくものになっていく。つまり、この yml に関しては、テンプレートや誰かのソースをコピペするだけでは決してうまくいかないものである。しっかりと本ドキュメントで yml の記述に必要な知識とノウハウを身につけて行って欲しい。
ID Unification では何を定義し (インプットとし)、何がアウトプットされるか?#
ID Unification で定義するもの (インプット)#
ここからは先ほどと少し観点を変えて、ID Unification に必要なインプットと主なアウトプットについて紹介することで、ID Unification の理解を深めていただきたいと思う。
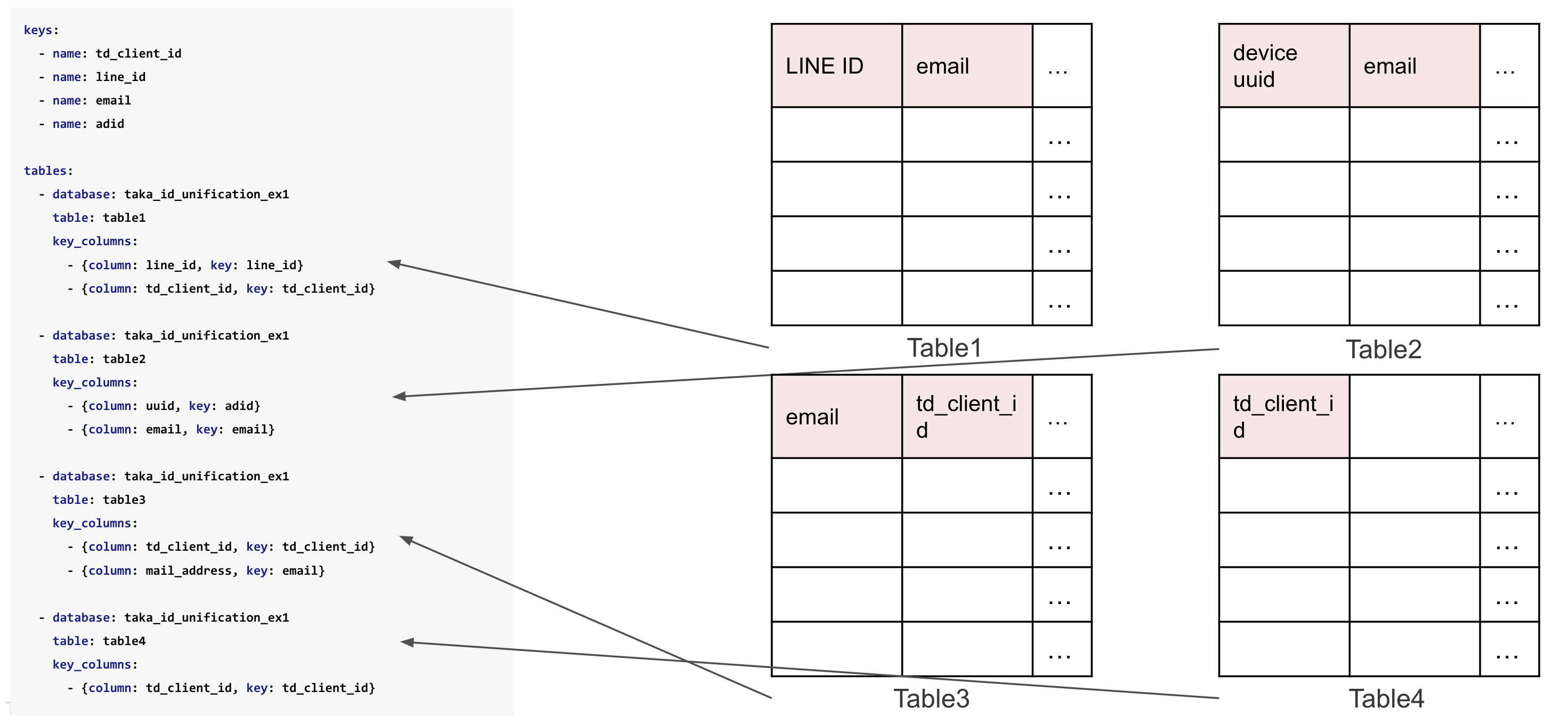
Fig. 2 定義するもの#
実態としてのインプットは、他のテーブルと縫い合わせられる識別子を持った全てのテーブルであり、これを全列挙していくことになる。また、各テーブルに含まれる (縫い合わせに使うための) 識別子を key として全列挙する。列挙された key を手がかりに、全テーブルを横断して縫い合わせを行っていくのだ。
ID Unification のアウトプット#
ID Unification の最も偉大なアウトプットは、特定した個人に付与される canonical_id と呼ばれるものである (出力されるテーブルの意味では lookup テーブル)。ただ、その canonical_id を活用するために、全てのソーステーブルに付与する作業などをユーザー側で行うのは大変である。そこで ID Unification は、ソーステーブルに canonical_id が付与した(エンリッチした)テーブルまで出力してくれる。
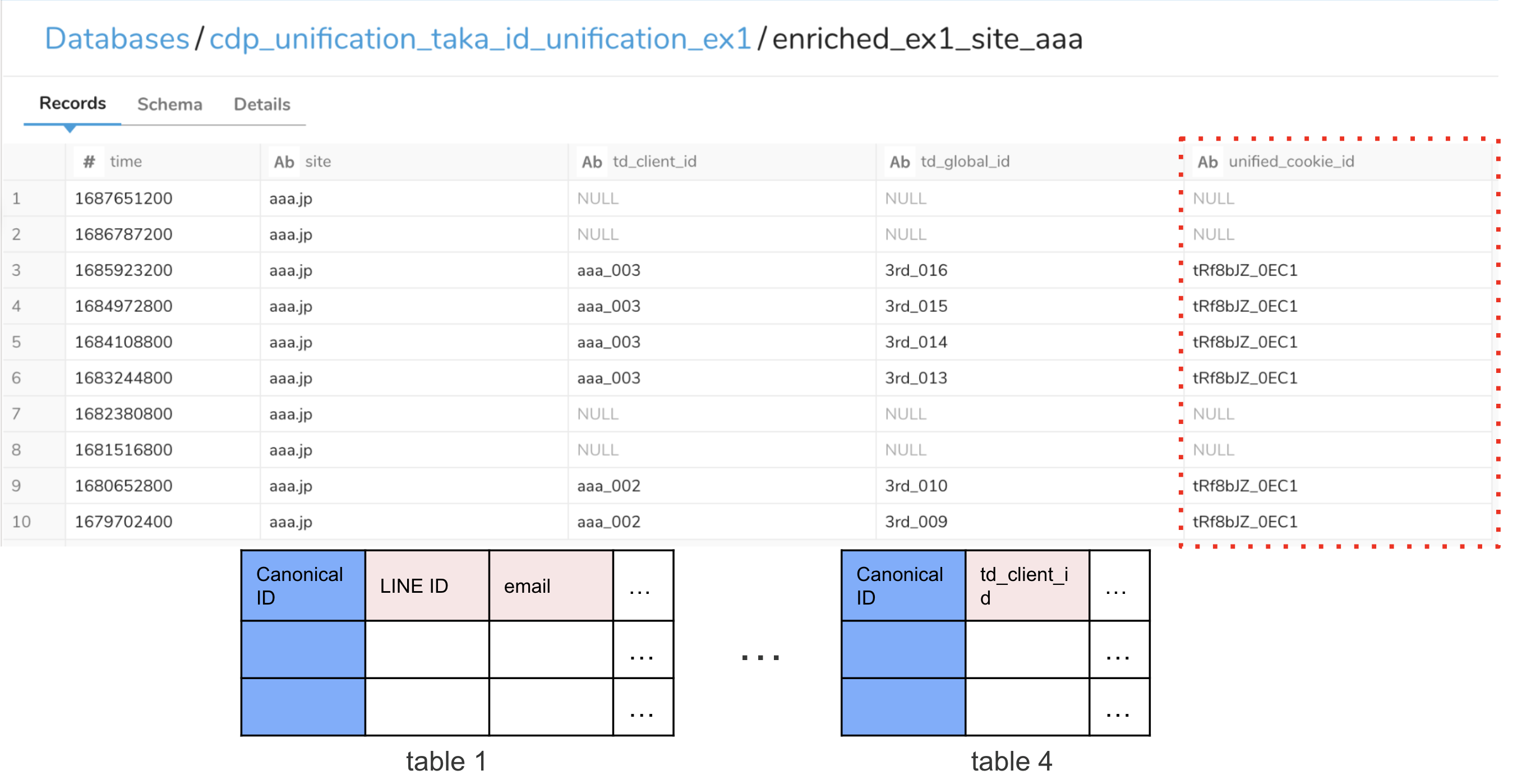
Fig. 3 アウトプット#
縫い合わせに使った全てのテーブルに、canonical_id と呼ばれる、ユーザーを識別するためのユニークな ID が付与される。例えば SQL で言えば、この ID を JOIN KEY に用いることで、他のテーブルの同一人物との縫い合わせが可能になり、ユーザー単位での集計・分析が可能になる。
ID Unification で定義するもの (インプット) for Audience Studio#
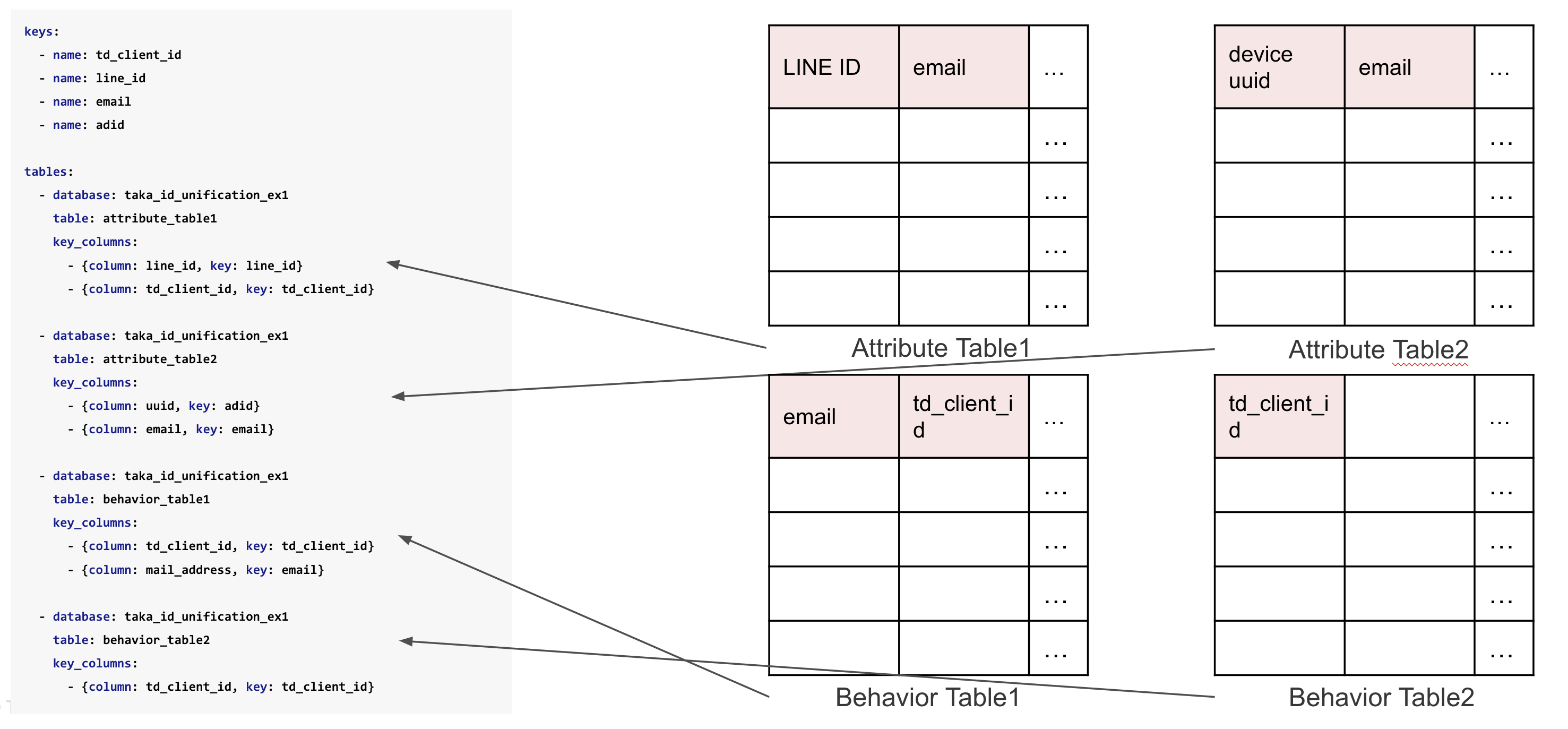
Fig. 4 定義するもの (Audience Studio)#
また、ID Unification はまさにオーディエンススタジオを使い始めるためのツールとも言える。 Master Segment に利用したい attribute_table、behavior_table をソーステーブルとして全て列挙し、かつ、テーブルに含まれる (縫い合わせに使う) 識別子を key として全て列挙する。
ID Unification のアウトプット for Audience Studio#
canonical_id がエンリッチされたテーブルに加えて、canonical_id を持った master_table が同時に出力される。
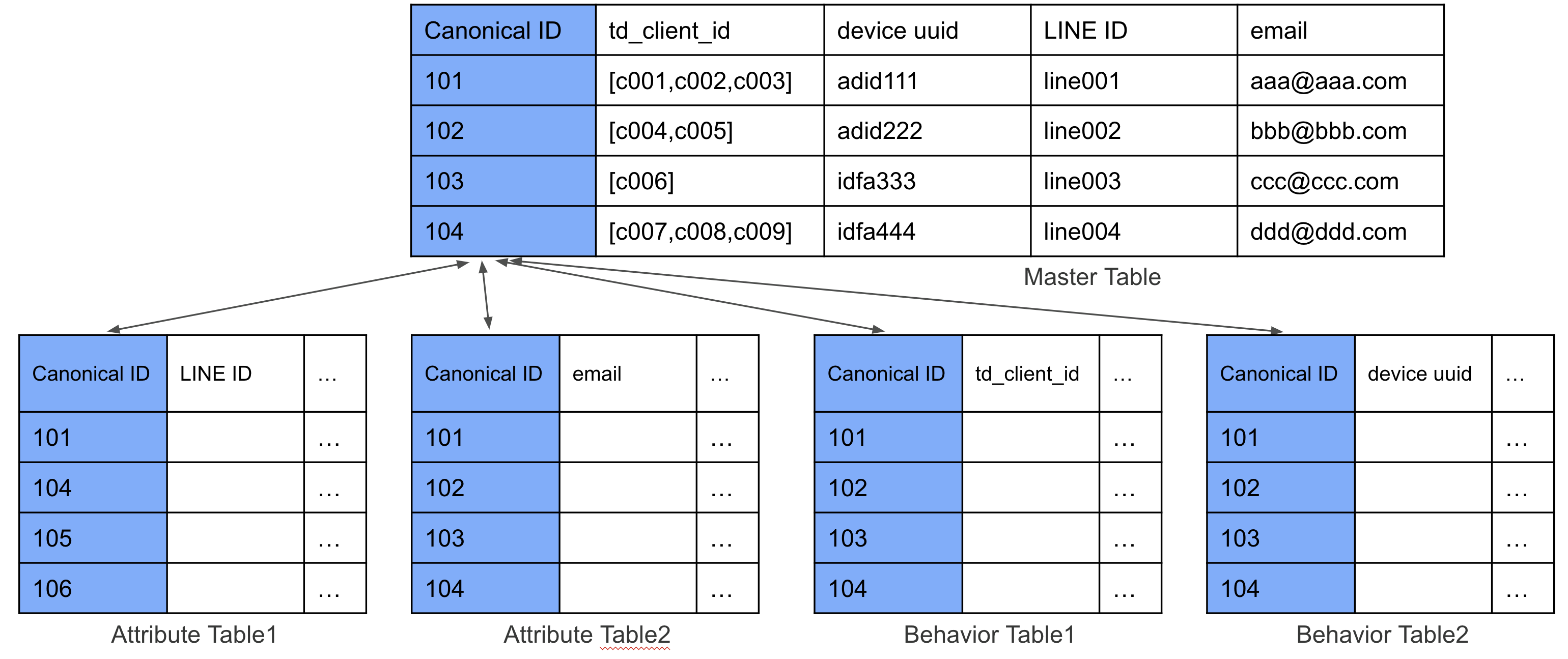
Fig. 5 アウトプット (Audience Studio)#
canonical_id をベースとする master_table が同時に出力されるため、Master Segment 作成に必要な、3つのテーブル: master_table / attribute_table / behavior_table に canonical_id がエンリッチされて出力されることになる。つまり Master Segment に必要な全てのテーブル群が準備できることになる。